The simplest way to remove non-alphanumeric characters from a string is to use regex:
if (string.IsNullOrEmpty(s))
return s;
return Regex.Replace(s, "[^a-zA-Z0-9]", "");
Code language: C# (cs)Note: Don’t pass in a null, otherwise you’ll get an exception.
Regex is the simplest options for removing characters by “category” (as opposed to removing arbitrary lists of characters or removing characters by position). The downside is that regex is the slowest option. If you’re concerned about the performance take a look at the performance section below.
This example is only keeping ASCII alphanumeric characters. If you’re working with other alphabets, see the section below about how to specify non-ASCII characters.
Table of Contents
For better performance, use a loop
Looping through the string and taking the characters you want is 7.5x faster than regex (and 3x faster than using Linq).
if (string.IsNullOrEmpty(s))
return s;
StringBuilder sb = new StringBuilder();
foreach(var c in s)
{
if ((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || (c >= '0' && c <= '9'))
sb.Append(c);
}
return sb.ToString();
Code language: C# (cs)Don’t bother using compiled regex
Using compiled regex doesn’t help much with performance in this scenario. In the best case, it’s slightly faster. In the worst case, it’s the same as not using compiled regex. It’s simpler to use the regex static methods (like Regex.Replace()), instead of trying to make sure the compiled regex object is available everywhere. In other words, just use the static regex methods instead of compiled regex.
Here’s an example of using compiled regex:
private static readonly Regex regex = new Regex("[^a-zA-Z0-9]", RegexOptions.Compiled);
public static string RemoveNonAlphanumericChars(string s)
{
if (string.IsNullOrEmpty(s))
return s;
return regex.Replace(s, "");
}
Code language: C# (cs)Use char.IsLetterOrDigit() if you want all Unicode alphanumeric characters
Be aware that char.IsLetterOrDigit() returns true for all Unicode alphanumeric characters. Usually when you’re stripping out characters, it’s because you know precisely which characters you want to take. Using char.IsLetterOrDigit() should only be used if you want to accept ALL Unicode alphanumeric characters and remove everything else. That should be rare.
It’s better to specify exactly which characters you want to keep (and then if you’re using regex, apply the ^ operator to remove everything but those characters).
Benchmark results
I compared the performance by benchmarking four approaches for removing non-alphanumeric characters from a string. I passed each method a string with 100 characters. The following graph shows the results:
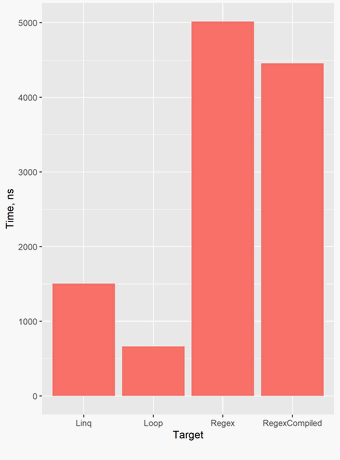
Here are all of the results:
Regex = 5016 ns (compiled = 4457 ns)
Linq = 1506 ns
Loop = 663 nsCode language: plaintext (plaintext)Specifying non-ASCII characters in regex
How about if you need to deal with non-ASCII alphanumeric characters, such as the following Greek characters:
ΕλληνικάCode language: plaintext (plaintext)If you’re dealing with a non-ASCII alphabet, like Greek, you can look up the Unicode range and use the code points or characters.
Note: Remember that this is about removing characters. So with regex, you specify which characters you want, and then use the ^ operator to match everything but those characters.
Use Unicode code points
Here’s an example of specifying the Greek Unicode code point range:
Regex.Replace(s, "[^Ͱ-Ͽ]", "");
Code language: C# (cs)Use Unicode named block
For better readability, you can use a Unicode named block, such as “IsGreek”. To specify that you want to use a named block, use \p{} like this:
Regex.Replace(s, @"[^\p{IsGreek}]", "");
Code language: C# (cs)Specify exactly which Unicode characters you want
You can specify exactly which Unicode characters you want (including a range of them):
Regex.Replace(s, "[^α-ωάΕ]", "");
Code language: C# (cs)This is easier to read than using code points.