There are five main aggregate functions in SQL: COUNT(), SUM(), AVG(), MIN(), and MAX(). These calculate aggregate values for sets of rows. When you use them with GROUP BY, they calculate the aggregate values for each group.
Let’s say you want to get movie streaming stats for each user. Here’s an example of using GROUP BY with all of the aggregate functions to get this result:
SELECT UserName,
COUNT(WatchedMins) as MoviesWatched,
SUM(WatchedMins) as TotalMinutes,
AVG(WatchedMins) as AvgMinutes,
MIN(WatchedMins) as MinMinutes,
MAX(WatchedMins) as MaxMinutes
FROM Streaming
GROUP BY UserName
Code language: SQL (Structured Query Language) (sql)Note: The aggregate functions accept a column name or a numeric expression (less common). COUNT() accepts a column name or * (I’ll explain that below).
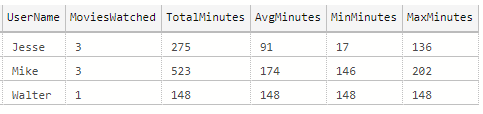
This query outputs the following results:
Handling NULLs
In the sample data, one of the rows has NULL in the column to aggregate (WatchedMins).
StreamedDate UserName Title WatchedMins
2023-01-06 Walter Jurassic World NULLCode language: plaintext (plaintext)By default, the aggregate functions ignore NULLs, so this row has no effect on the aggregate values. You can handle NULLs differently, which I’ll explain below.
Count all rows
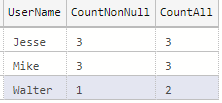
When you use COUNT() with a column name, it doesn’t count rows with NULLs in the column. If you want to count all rows, use COUNT(*). Here’s an example to show the difference:
SELECT UserName,
COUNT(WatchedMins) as CountNonNull,
COUNT(*) as CountAll
FROM Streaming
GROUP BY UserName
Code language: SQL (Structured Query Language) (sql)This outputs the following results. Notice the count difference in the highlighted row:
Use ISNULL() to provide a default value
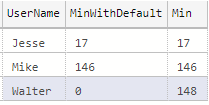
Sometimes you may want to provide a default value to the aggregate functions for when a row is NULL. You can do that by using ISNULL(). Here’s an example:
SELECT UserName,
MIN(ISNULL(WatchedMins, 0)) as MinWithDefault,
COUNT(*) as CountAllRows
FROM Streaming
GROUP BY UserName
Code language: SQL (Structured Query Language) (sql)This outputs the following results. Notice the difference in the highlighted row:
Alias the aggregate result column
It’s a good idea to alias the aggregate result column (i.e. COUNT(*) as Count), otherwise you end up with a blank / default column in the results. This can be a problem if you need to map the query results in code or save the results (like to a CSV file).
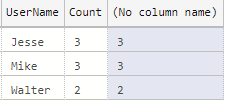
Here’s an example to show the difference between an aliased and non-aliased aggregate result column:
SELECT UserName,
COUNT(*) as [Count],
COUNT(*)
FROM Streaming
GROUP BY UserName
Code language: SQL (Structured Query Language) (sql)This outputs the following. Notice the highlighted column has no column name:
Using aggregate functions without GROUP BY
The aggregate functions work on sets of rows. You can use them with or without GROUP BY. For example, here’s an example of calculating the aggregate values for the entire table:
SELECT
COUNT(WatchedMins) as MoviesWatched,
SUM(WatchedMins) as TotalMinutes,
AVG(WatchedMins) as AvgMinutes,
MIN(WatchedMins) as MinMinutes,
MAX(WatchedMins) as MaxMinutes
FROM Streaming
Code language: SQL (Structured Query Language) (sql)Note: You can include a WHERE clause to calculate aggregate values on a subset of the table’s rows.
This outputs the following results:
