In regex, capturing groups give you a way to save text and refer to it later. Capturing groups can be named, and referred to by their name. When they aren’t named, you refer to them by their index number.
In this article, I’ll show how to use named capturing groups by solving the problem of extracting data out of Kindle highlights from a book I just finished reading.
1 – Get the raw data
First of all, here is a snippet of a few highlights from a book I read:
Your Kindle Notes For:
Fooled by Randomness: The Hidden Role of Chance in Life and in the Markets (Incerto Book 1)
Nassim Nicholas Taleb
Last accessed on Monday March 2, 2020
Note(s)
Yellow highlight | Page: 243
You attribute your successes to skills, but your failures to randomness.
Yellow highlight | Page: 248
A more human version can be read in Seneca’s Letters from a Stoic, a soothing and surprisingly readable book that I distribute to my trader friends (Seneca also took his own life when cornered by destiny).
Yellow highlight | Page: 249
Self-help books (even when they are not written by charlatans) are largely ineffectual.
Yellow highlight | Page: 249
The only article Lady Fortuna has no control over is your behavior. Good luck.Code language: plaintext (plaintext)Note: When you make highlights in an Amazon Kindle ebook, they save your highlighted passages (as shown above) and they make these available to you in your Amazon account.
2 – Determine what data you want to extract
I want the page number and the highlighted text. For example, I want to convert this line:
Yellow highlight | Page: 249
The only article Lady Fortuna has no control over is your behavior. Good luck.Code language: plaintext (plaintext)Into this:
| Page | Text |
| 249 | The only article Lady Fortuna has no control over is your behavior. Good luck. |
3 – Write the regex
I always use .NET Regex Tester to write regex and test it quickly.
Here is the regex to extract the Page and Text from the highlights data.
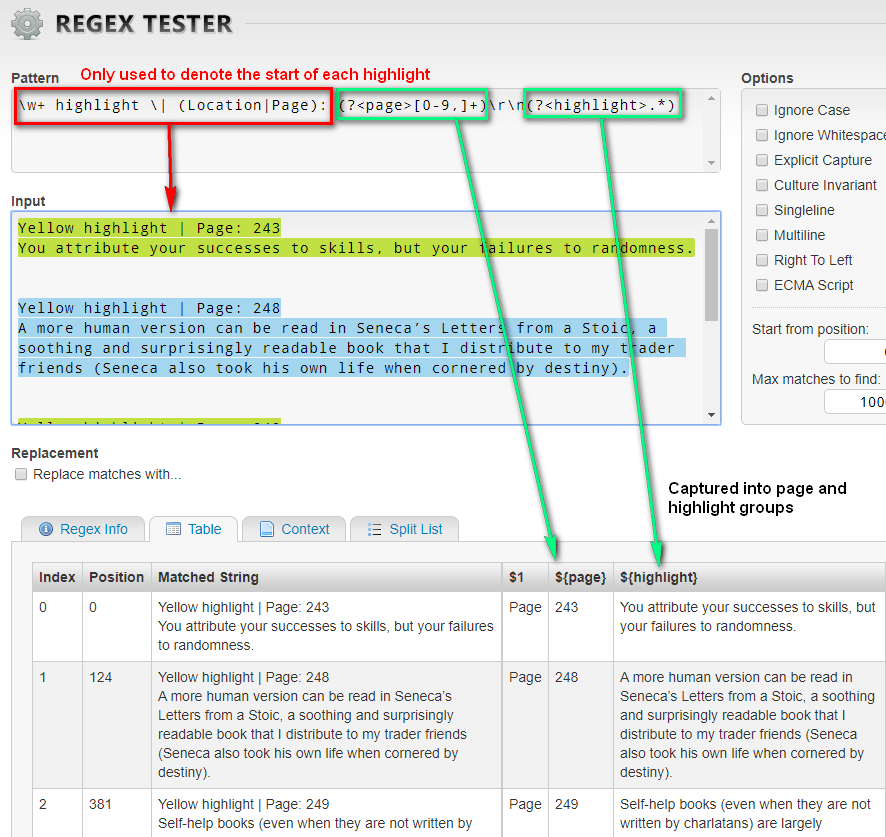
Explaining this regex
I’m going to break down and explain the regex statement above.
\w+ highlight \| (Location|Page): Code language: plaintext (plaintext)The purpose of this is to find the start of each highlight.
| Regex | Explanation |
| \w+ highlight | Matches one or more alphanumeric characters followed by the literal “highlight”. I could’ve specified the colors instead of matching any words, like this (Blue|Yellow), but I used \w+ instead because I don’t want to have to fix this if Kindle adds more colors. |
| \| | Matches a pipe character “|”. This has to be escaped with “\” because “|” is an operator in regex. |
| (Location|Page): | Matches the word “Location: ” or “Page: “. I’ve seen both in Kindle highlights. |
Now that the start of each highlight block is known, the second part of the regex is used to capture the data that I want to extract from the highlight block.
(?<page>[0-9,])\r\nCode language: plaintext (plaintext)| Regex | Explanation |
| () | Capturing group. Anything within the parentheses is part of the captured group and can be referenced later on. |
| ?<page> | Names this capturing group “page”. This group can be referenced by the name “page” later on. |
| [0-9,] | Matches digits and commas. Ex: 99, 100, 1,000 |
| \r\n | Matches a Windows newline. |
(?<highlight>.*)Code language: plaintext (plaintext)| Regex | Explanation |
| () | Capturing group |
| ?<highlight> | Names the capturing group “highlight”. |
| .* | Matches everything |
4 – Use the regex in code
using System;
using System.Collections.Generic;
using System.Text.RegularExpressions;
namespace RegexCapturingGroups
{
public class KindleHighlight
{
public int Page { get; set; }
public string Text { get; set; }
}
public class KindleHighlightParser
{
private static readonly Regex regex = new Regex(@"\w+ highlight \| (Location|Page): (?<page>[0-9,]+)\r\n(?<highlight>.*)", RegexOptions.Compiled);
public List<KindleHighlight> ParseHighlights(string rawHighlightData)
{
var kindleHighlights = new List<KindleHighlight>();
foreach (Match match in regex.Matches(rawHighlightData))
{
kindleHighlights.Add(new KindleHighlight()
{
Page = Convert.ToInt32(match.Groups["page"].Value),
Text = match.Groups["higlight"].Value
});
}
return kindleHighlights;
}
}
}
Code language: C# (cs)