Let’s say you want to search for specific characters in a large text file and return a list of context objects to the calling code for further processing (such as showing the results in the UI).
One way to do that is to build the entire list at once and return it. If you don’t really need the entire list of objects, then this is really inefficient. It’s holding all of objects in memory when it doesn’t need to.
This is where yield return helps. Instead of returning the entire list at once, it returns one object at a time. This minimizes memory usage significantly.
Here’s an example of using yield return to implement the “find chars” functionality discussed above. Notice that this method is returning an IEnumerable.
public static IEnumerable<CharFound> FindChars(string filePath, HashSet<char> charsToFind)
{
using (var sr = new StreamReader(filePath))
{
int position = 0;
while (!sr.EndOfStream)
{
char c = (char)sr.Read();
if (charsToFind.Contains(c))
{
yield return new CharFound()
{
Char = c,
Position = position
};
}
position++;
}
}
}
Code language: C# (cs)The calling code can loop over the results.
var charsToFind = new HashSet<char>() { '0', '1' };
foreach(var charFound in FindChars(@"C:\temp\guids.txt", charsToFind))
{
Console.WriteLine($"Found {charFound.Char} at position {charFound.Position}");
}
Code language: C# (cs)It writes the information to the console as each CharFound object is returned:
Found 1 at position 0
Found 0 at position 12
Found 0 at position 24
Found 1 at position 28
Found 1 at position 30
Found 0 at position 39
Found 1 at position 47
Found 0 at position 50
...Performance comparison showing the efficiency of yield return
I compared the performance of using yield return vs creating an entire collection at once by writing 10 million guid strings to a file multiple times. I used the Memory Usage profiler tool in Visual Studio to check the max memory the processes used over time.
Here is the yield return code:
public static IEnumerable<string> GetGuids(int count)
{
for(int i = 0; i < count; i++)
{
yield return Guid.NewGuid().ToString();
}
}
//Save to a file
System.IO.File.WriteAllLines(@"C:\temp\guids.txt", GetGuids(10_000_000));
Code language: C# (cs)Here is the memory usage over time. The process used a max of 12 MB, and it didn’t grow while continuously writing 10 million strings to a file.
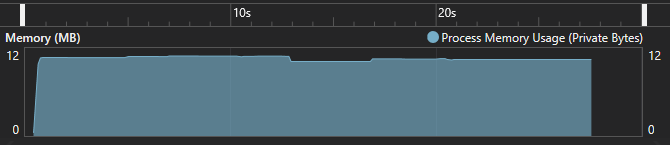
Here is the code that adds 10 million strings to a list, then writes the list of strings to a file:
public static List<string> GetGuidsList(int count)
{
var list = new List<string>();
for (int i = 0; i < count; i++)
{
list.Add(Guid.NewGuid().ToString());
}
return list;
}
//Save to a file
System.IO.File.WriteAllLines(@"C:\temp\guids.txt", GetGuidsList(10_000_000));
Code language: C# (cs)Here is the memory usage over time. The process used an average of 1.5 GB and got close to using 2 GB at one point. That’s an enormous amount of memory.
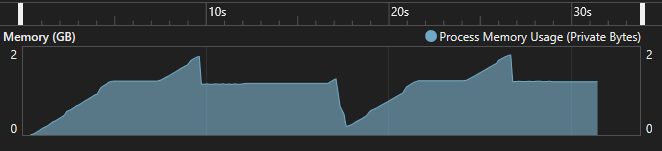
The difference in max memory usage – 12 MB vs 2 GB – is huge. This shows how yield return can be used to minimize memory usage when dealing with large collections.
This isn’t the same as comparing the total memory allocated (like the measure you get with Benchmark.NET’s MemoryDiagnoser).
To see the difference, take a look at this table (after writing 10 million strings to a file once):
| Method | Total memory allocated | Max memory usage at any given time |
| yield return | 915 MB | 12 MB |
| Creating the entire collection at once | > 1 GB | > 1 GB |
When dealing with a large number of objects, it still has to create them all, hence why the total memory allocated is still high. The main benefit of yield return is that it minimizes the amount of memory being used at any given time.